Apache Beam: A Unified Framework for Batch and Stream Processing
Introduction
Apache Beam is an open-source, unified programming model that enables developers to build efficient and scalable batch and stream data processing pipelines. Originally developed by Google, Apache Beam is now a part of the Apache Software Foundation and supports multiple execution engines, such as Apache Flink, Apache Spark, and Google Cloud Dataflow. Its flexibility makes it a preferred choice for handling large-scale data processing.
Why Apache Beam?
Apache Beam stands out due to its portability, scalability, and advanced features:
Unified Processing: A single API for batch and streaming data processing.
Portability: Write once, run anywhere with support for multiple runners (Flink, Spark, Dataflow, Samza, etc.).
Scalability and Efficiency: Handles large-scale, real-time data efficiently.
Multi-Language Support: Compatible with Java, Python, and Go.
Advanced Features: Offers event-time processing, windowing, triggers, and stateful computations.
Apache Beam Architecture
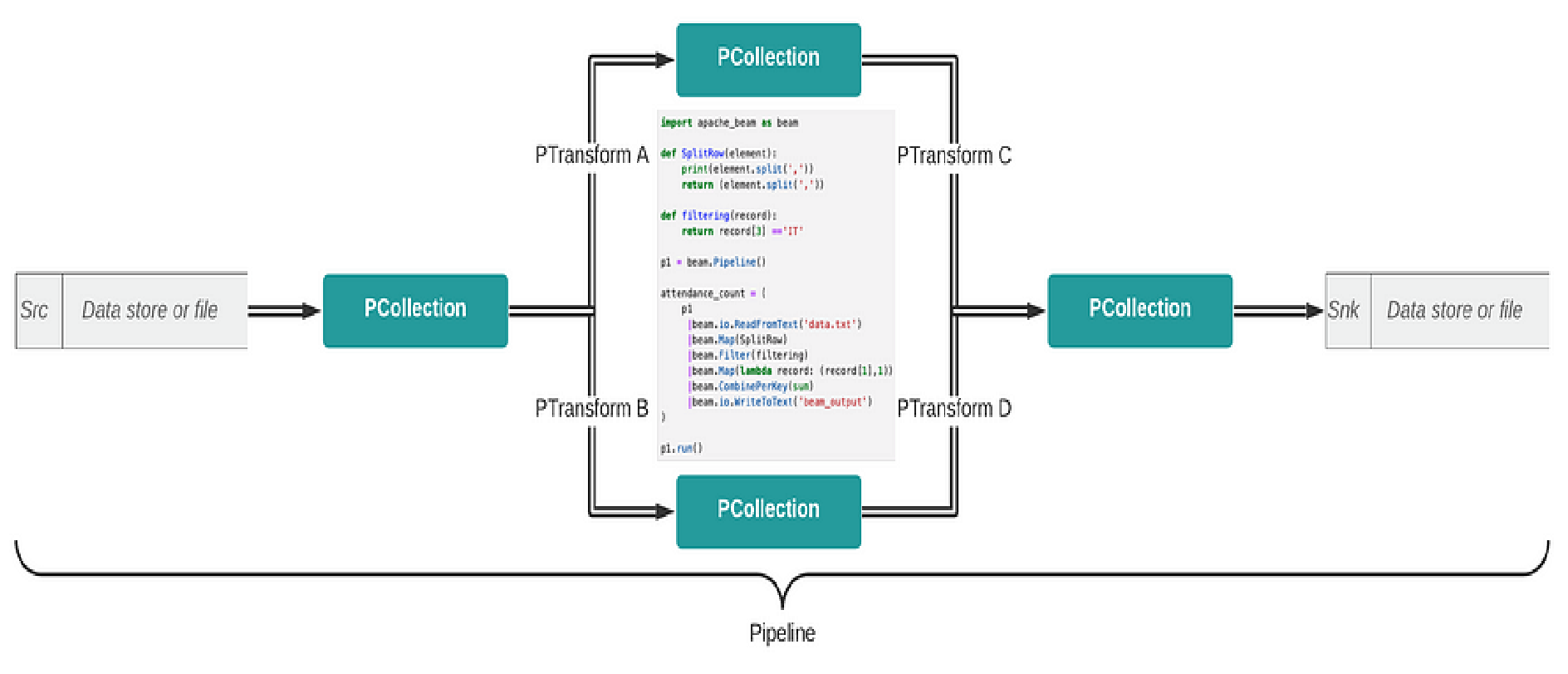
The architecture of Apache Beam consists of five key components:
1. Pipeline
Defines the overall workflow, from data input to output.
2. PCollection
Represents the dataset being processed. It can be bounded (fixed size) or unbounded (continuous stream).
3. Transformations
Operations applied to PCollections, such as:
ParDo – Parallel computation on elements.
GroupByKey – Aggregation of data.
Windowing – Divides data based on time intervals.
4. Pardo (Parallel Do)
Executes computations in parallel to speed up data processing.
5. Runners
Apache Beam pipelines can be executed on various distributed processing engines like Apache Flink, Apache Spark, Google Cloud Dataflow, and Apache Samza.
Supported Runners in Apache Beam
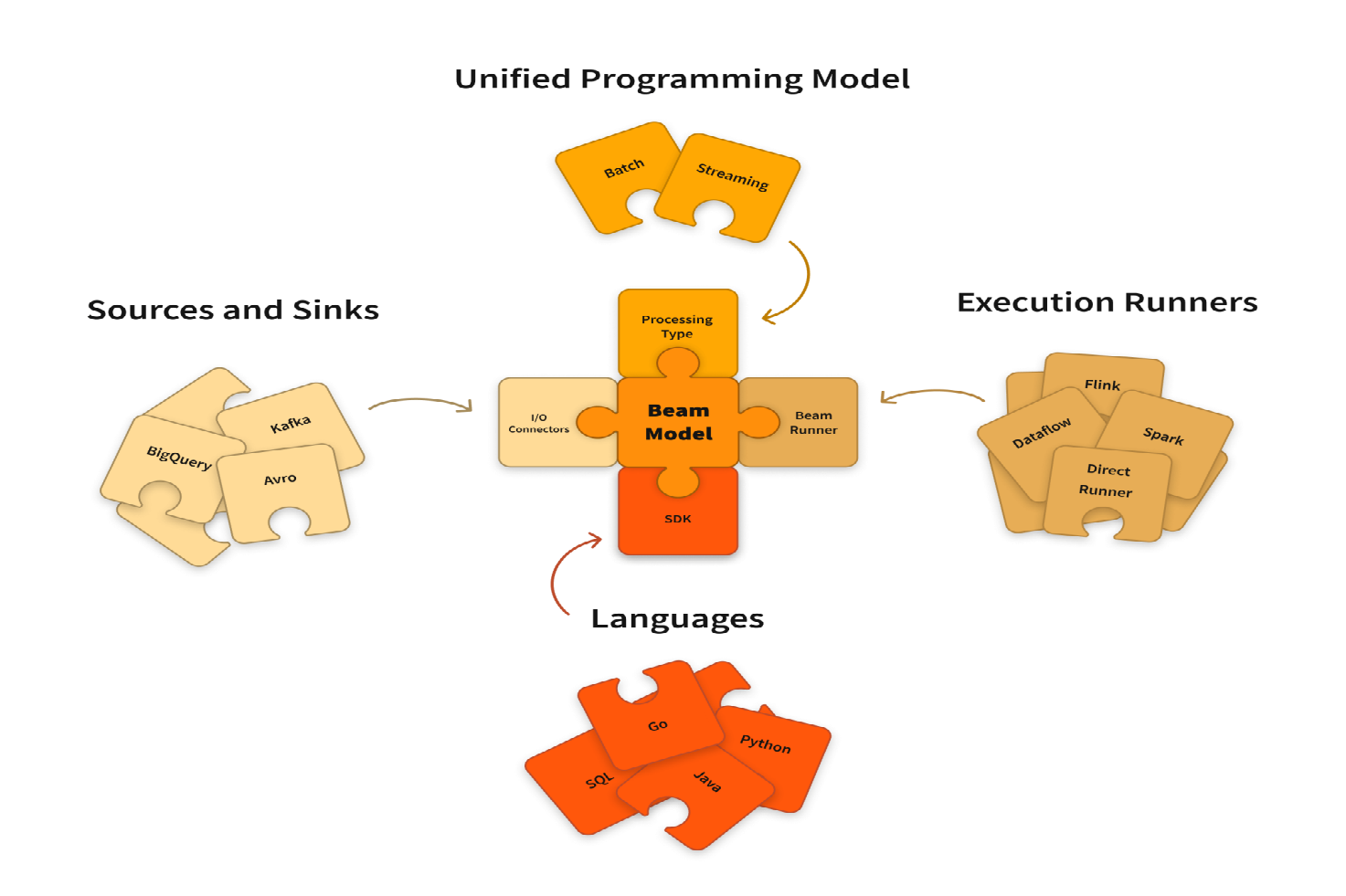
Apache Beam can be executed on different runners, depending on the use case:
Apache Flink: Best for low-latency stream processing.
Apache Spark: Optimized for batch processing and machine learning.
Google Cloud Dataflow: Fully managed execution service for Beam pipelines.
Apache Samza: Designed for real-time Kafka stream processing.
Direct Runner: Useful for local testing and debugging.
Key Technologies in Apache Beam
Apache Beam incorporates advanced technologies that make it a powerful framework:
Dataflow Model: Implements the Google Dataflow Model for unified batch and stream processing.
Event Time Processing: Processes events based on the actual time they occurred.
Windowing and Triggers: Handles unbounded streaming data by grouping events over time.
Stateful Processing: Maintains state across multiple events in a stream.
Side Inputs and Outputs: Supports additional datasets and multiple output destinations.
Platform Integration
Apache Beam integrates with multiple platforms for seamless data ingestion, storage, and processing:
Compute Frameworks: Google Cloud Dataflow, Apache Flink, Apache Spark.
Messaging Systems: Apache Kafka, Google Pub/Sub, AWS Kinesis.
Storage Solutions: BigQuery, HDFS, Amazon S3, Google Cloud Storage.
AI/ML Pipelines: TensorFlow Extended (TFX), Vertex AI, AWS SageMaker.
Real-World Applications of Apache Beam
Apache Beam is widely used across industries for real-time and batch data processing.
Fraud Detection – Detects suspicious transactions in real time (used in banking and FinTech).
IoT Data Processing – Processes real-time sensor data from smart devices.
Log Analysis and Monitoring – Analyzes server logs to detect security threats.
Recommendation Systems – Personalizes product suggestions in e-commerce.
Sentiment Analysis – Analyzes social media data for market research.
Industry Use Cases
1. Financial Services
Fraud detection and real-time risk analysis.
Compliance monitoring for AML (Anti-Money Laundering) regulations.
2. E-commerce and Retail
Real-time product recommendations.
Customer insights for targeted marketing.
3. Healthcare
Real-time monitoring of patient vitals from IoT devices.
Medical record analysis and anomaly detection.
4. IoT and Smart Cities
Traffic optimization using real-time GPS data.
Environmental monitoring to detect pollution levels.
5. Cybersecurity
Intrusion detection and network security analysis.
Log monitoring to detect security breaches.
Advantages of Apache Beam
Apache Beam provides significant benefits:
Unified API – One framework for batch and streaming processing.
Portability – Runs on multiple execution engines.
Scalability – Handles large-scale, high-throughput data workloads.
Rich Ecosystem – Integrates with Kafka, Pub/Sub, BigQuery, and more.
Performance Optimization – Uses parallel processing to improve efficiency.
Conclusion
Apache Beam is a powerful, flexible, and scalable framework for processing both real-time and batch data. Its portability, unified API, and support for multiple execution engines make it a preferred choice for organizations handling big data workflows. From banking and e-commerce to healthcare and IoT, Apache Beam powers real-world applications across industries.